Criticism 3 of NHST: Essential Information is Lost When Transforming 2D Data into a 1D Measure
Introduction
Continuing on with my series on the weaknesses of NHST, I’d like to focus on an issue that’s not specific to NHST, but rather one that’s relevant to all quantitative analysis: the destruction caused by an inappropriate reduction of dimensionality. In our case, we’ll be concerned with the loss of essential information caused by the reduction of a two-dimensional world of uncertain measurements into the one-dimensional world of p-values.
p-Values Mix Up the Strength of Effects with the Precision of Their Measurement
For NHST, the two independent dimensions of measurement are (1) the strength of an effect, measured using the distance of a point estimate from zero; and (2) the uncertainty we have about the effect’s true strength, measured using something like the expected variance of our measurement device. These two dimensions are reduced into a single p-value in a way that discards much of the meaning of the original data.
When using confidence intervals, the two dimensions I’ve described are equivalent to the position of the center of the confidence interval relative to zero and the width of the confidence interval. Clearly these two dimensions can vary independently. Working through the math, it is easy to show that p-values are simply a one-dimensional representation of these two dimensions. (See footnote.)
To illustrate how many different kinds of data sets receive the same p-value under NHST, let’s consider three very different data sets in which we test for a difference across two groups and then get the same p-value out of our analysis:
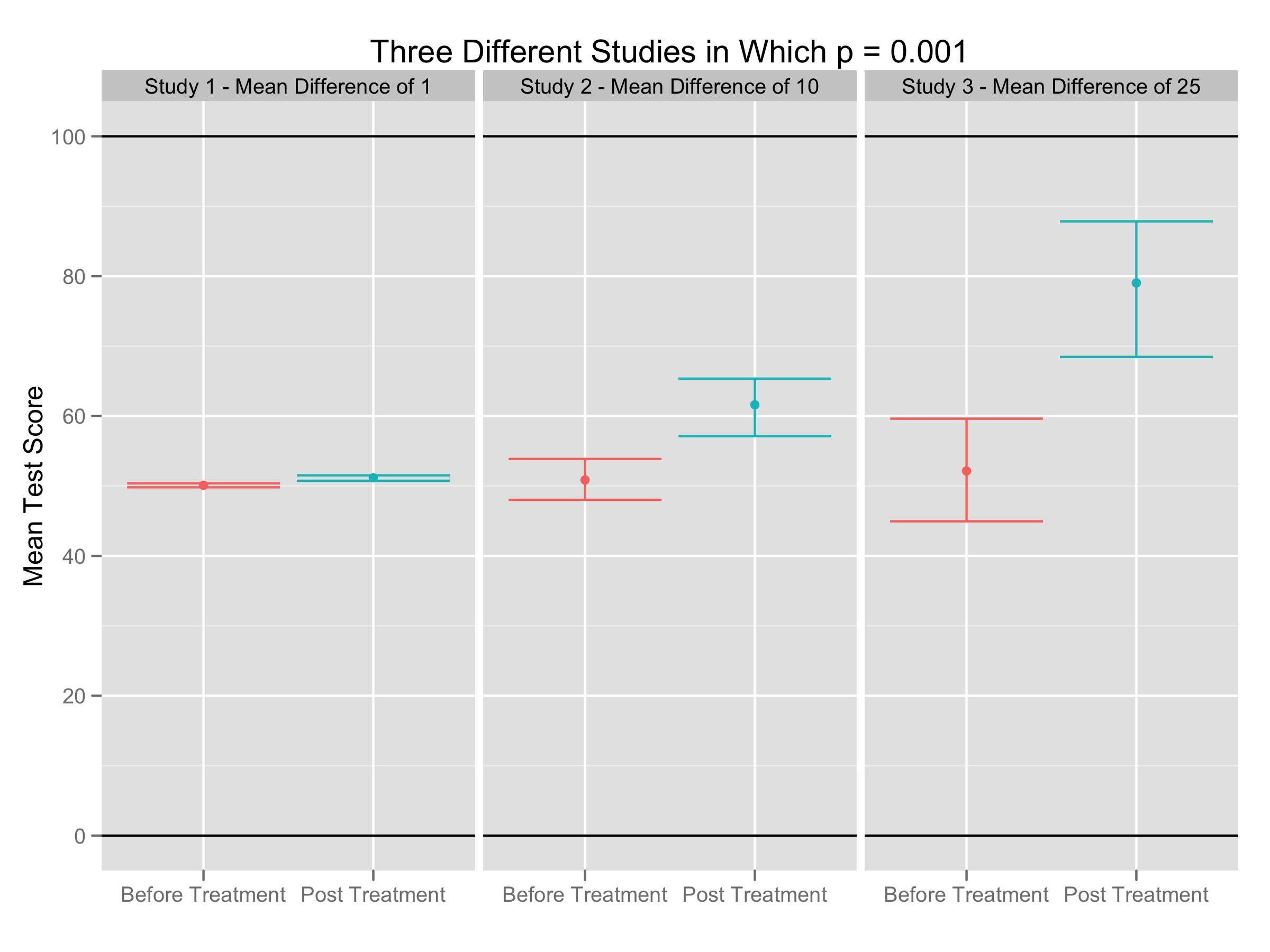
Clearly these data sets are substantively different, despite producing identical p-values. Really, we’ve seen three qualitatively different types of effects under study:
- An effect that is probably trivial, but which has been measured with considerable precision.
- An effect with moderate importance that has been measured moderately well.
- An effect that could be quite important, but which has been measured fairly poorly.
No one can argue that these situations are not objectively different. Importantly, I think many of us also feel that the scientific merits of these three types of research are very different: we have some use for the last two types of studies and no real use for the first. Sadly, I suspect that the scientific literature increasingly focuses on the first category, because it is always possible to measure anything precisely if you are willing to invest enough time and money. If the community’s metric for scientific quality is a p-value, which can be no more than a statement about the precision of measurements, then you will find that scientists produce precise measurements of banalities rather than tentative measurements of important effects.
How Do We Solve This Problem?
Unlike previous posts, this problem with the use of NHST can be solved without any great effort to teach people to use better methods: to compute a p-value, you need to estimate both the strength of an effect and the precision of its measurement. Moving forward, we must be certain that we report both of these quantities instead of the one-number p-value summary.
Sadly, people have been arguing for this change for years without much success. To solve our impasse, I think we need to push on our community to impose a flat out ban: going forward, researchers should only be allowed to report confidence intervals. Given that p-values can always be derived from the more informative confidence intervals while the opposite transformation is not possible, how compelling could any argument be for continuing to tolerate p-values?
References
Ziliak, S.T. and McCloskey, D.N. (2008), “The cult of statistical significance: How the standard error costs us jobs, justice, and lives”, Univ of Michigan Press
Footnote: Indeed, p-values are effectively constructed by dividing the distance of the point estimate from zero by the width of the confidence interval and then passing this normalized distance through a non-linear function. I’m particularly bewildered by the use of this non-linear function: most people have trouble interpreting numbers already, and this transformation seems almost designed to make the numbers harder to interpret.