Recently a few members of R Core have indicated that part of what slows down the development of R as a language is that it has become increasingly difficult over the years to achieve consensus among the core developers of the language. Inspired by these claims, I decided to look into this issue quantitatively by measuring the quantity of commits to R’s SVN repository that were made by each of the R Core developers. I wanted to know whether a small group of developers were overwhelmingly responsible for changes to R or whether all of the members of R Core had contributed equally. To follow along with what I did, you can grab the data and analysis scripts from GitHub.
First, I downloaded the R Core team’s SVN logs from http://developer.r-project.org/. I then used a simple regex to parse the SVN logs to count commits coming from each core committer.
After that, I tabulated the number of commits from each developer, pooling across the years 2003-2012 for which I had logs. You can see the results below, sorted by total commits in decreasing order:
| Committer | Total Number of Commits |
|---|---|
| ripley | 22730 |
| maechler | 3605 |
| hornik | 3602 |
| murdoch | 1978 |
| pd | 1781 |
| apache | 658 |
| jmc | 599 |
| luke | 576 |
| urbaneks | 414 |
| iacus | 382 |
| murrell | 324 |
| leisch | 274 |
| tlumley | 153 |
| rgentlem | 141 |
| root | 87 |
| duncan | 81 |
| bates | 76 |
| falcon | 45 |
| deepayan | 40 |
| plummer | 28 |
| ligges | 24 |
| martyn | 20 |
| ihaka | 14 |
After that, I tried to visualize evolving trends over the years. First, I visualized the number of commits per developer per year:
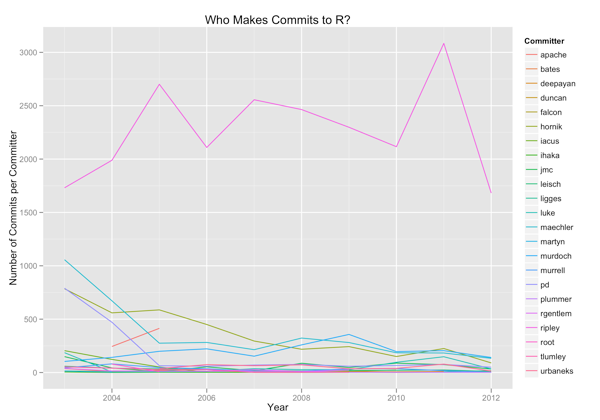
And then I visualized the evenness of contributions from different developers by measuring the entropy of the distribution of commits on a yearly basis:
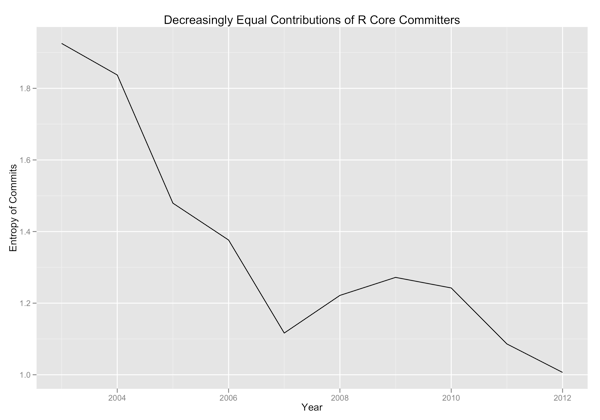
There seems to be some weak evidence that the community is either finding consensus more difficult and tending towards a single leader who makes final decisions or that some developers are progressively dropping out because of the difficulty of achieving consensus. There is unambiguous evidence that a single developer makes the overwhelming majority of commits to R’s SVN repo.
I leave it to others to understand what all of this means for R and for programming language communities in general.