Introduction Link to heading
A few months ago, Drew Conway and I gave a webcast that tried to teach people about the basic principles behind linear and logistic regression. To illustrate logistic regression, we worked through a series of progressively more complex spam detection problems.
The simplest data set we used was the following:
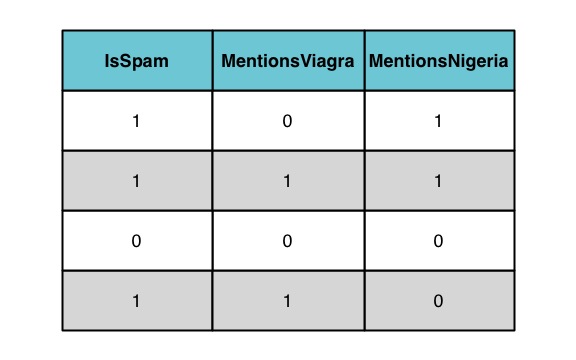
This data set has one clear virtue: the correct classifier defines a decision boundary that implements a simple OR operation on the values of MentionsViagra and MentionsNigeria. Unfortunately, that very simplicity causes the logistic regression model to break down, because the MLE coefficients for MentionsViagra and MentionsNigeria should be infinite. In some ways, our elegantly simple example for logistic regression is actually the statistical equivalent of a SQL injection.
In our webcast, Drew and I decided to ignore that concern because R produces a useful model fit despite the theoretical MLE coefficients being infinite:
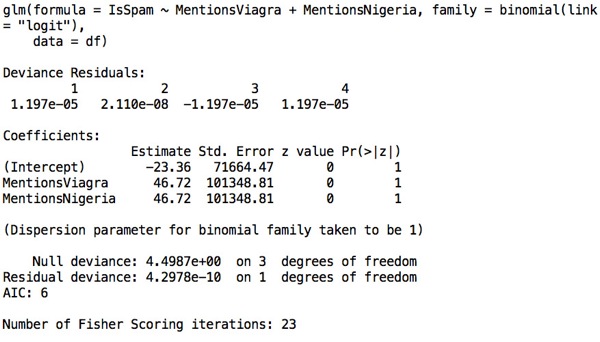
Although R produces finite coefficients here despite theory telling us to except something else, I should note that R does produce a somewhat cryptic warning during the model fitting step that alerts the very well-informed user that something has gain awry:
glm.fit: fitted probabilities numerically or 1 occurred
It seems clear to me that R’s warning would be better off if it were substantially more verbose:
Warning from
glm.fit():Fitted probabilities could not be distinguished from 0’s or 1’s under finite precision floating point arithmetic. As a result, the optimization algorithm for GLM fitting may have failed to converge. You should check whether your data set is linearly separable.
Broader Questions Link to heading
Although I’ve started this piece with a very focused example of how R’s implementation of logistic regression differs from the purely mathematical definition of that model, I’m not really that interested in the details of how different pieces of software implement logistic regression. If you’re interested in learning more about that kind of thing, I’d suggest reading the excellent piece on R’s logistic regression function that can be found on the Win-Vector blog.
Instead, what interests me right now are a set of broader questions about how statistical software should work. What is the standard for correctness for statistical software? And what is the standard for usefulness? And how closely related are those two criteria?
Let’s think about each of them separately:
- Usefulness: If you want to simply make predictions based on your model, then you want R to produce a fitted model for this data set that makes reasonably good predictions on the training data. R achieves that goal: the fitted predictions for R’s logistic regression model are numerically almost indistinguishable from the 0/1 values that we would expect from a maximum likelihood algorithm. If you want useful algorithms, then R’s decision to produce some model fit is justified.
- Correctness: If you want software to either produce mathematically correct answers or to die trying, then R’s implementation of logistic is not for you. If you insist on theoretical purity, it seems clear that R should not merely emit a warning here, but should instead throw an inescapable error rather than return an imperfect model fit. You might even want R to go further and to teach the end-user about the virtues of SVM’s or the general usefulness of parameter regularization. Whatever you’d like to see, one thing is sure: you definitely do not want R to produce model fits that are mathematically incorrect.
It’s remarkable that such a simple example can bring the goals of predictive power and theoretical correctness into such direct opposition. In part, the conflict arises here because those purely theoretical concerns are linked by a third consideration: computer algorithms are not generally equivalent to their mathematical idealizations. Purely computational concerns involving floating-point imprecision and finite compute time mean that we cannot generally hope for computers to produce answers similar to those prescribed by theoretical mathematics.
What’s fascinating about this specific example is that there’s something strangely desirable about floating-point numbers having finite precision: no one with any practical interest in modeling is likely to be interested in fitting a model with infinite-valued parameters. R’s decision to blindly run an optimization algorithm here unwittingly achieves a form of regularization like that employed in early stopping algorithms for fitting neural networks. And that may be a good thing if you’re interested in using a fitted model to make predictions, even though it means that R produces quantities like standard errors that have no real coherent interpretation in terms of frequentist estimators.
Whatever your take is on the virtues or vices of R’s implementation of logistic regression, there’s a broad take away from this example that I’ve been dealing with constantly while working on Julia: any programmer designing statistical software has to make decisions that involve personal judgment. The requirement for striking a compromise between correctness and usefulness is so nearly omnipresent that one of the most popular pieces of statistical software on Earth implements logistic regression using an algorithm that a pure theorist could argue is basically broken. But it produces an answer that has practical value. And that might just be the more important thing for statistical software to do.