Writing Better Statistical Programs in R
A while back a friend asked me for advice about speeding up some R code that they’d written. Because they were running an extensive Monte Carlo simulation of a model they’d been developing, the poor performance of their code had become an impediment to their work.
After I looked through their code, it was clear that the performance hurdles they were stumbling upon could be overcome by adopting a few best practices for statistical programming. This post tries to describe some of the simplest best practices for statistical programming in R. Following these principles should make it easier for you to write statistical programs that are both highly performant and correct.
Write Out a DAG
Whenever you’re running a simulation study, you should appreciate the fact that you are working with a probabilistic model. Even if you are primarily focused upon the deterministic components of this model, the presence of any randomness in the model means that all of the theory of probabilistic models applies to your situation.
Almost certainly the most important concept in probabilistic modeling when you want to write efficient code is the notion of conditional independence. Conditional independence is important because many probabilistic models can be decomposed into simple pieces that can be computed in isolation. Although your model contains many variables, any one of these variables may depend upon only a few other variables in your model. If you can organize all of variables in your model based on their dependencies, it will be easier to exploit two computational tricks: vectorization and parallelization.
Let’s go through an example. Imagine that you have the model shown below:
$$ X \sim \text{Normal}(0, 1) $$
$$ Y1 \sim \text{Uniform}(X, X + 1) $$
$$ Y2 \sim \text{Uniform}(X - 1, X) $$
$$ Z \sim \text{Cauchy}(Y1 + Y2, 1) $$
In this model, the distribution of Y1 and Y2 depends only on the value of X. Similarly, the distribution of Z depends only on the values of Y1 and Y2. We can formalize this notion using a DAG, which is a directed acyclic graph that depicts which variables depend upon which other variables. It will help you appreciate the value of this format if you think of the arrows in the DAG below as indicating the flow of causality:
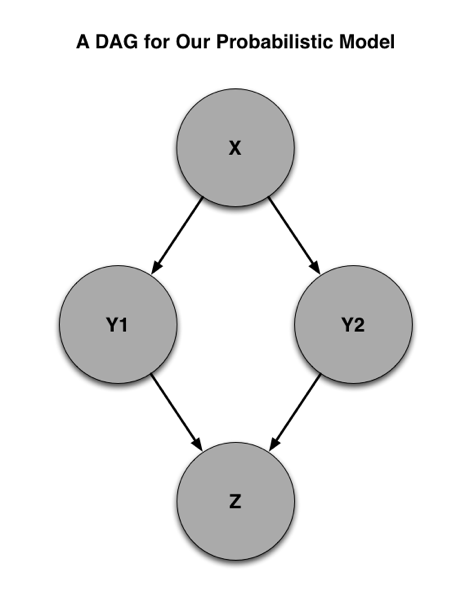
Having this DAG drawn out for your model will make it easier to write efficient code, because you can generate all of the values of a variable V simultaneously once you’ve computed the values of the variables that V depends upon. In our example, you can generate the values of X for all of your different simulations at once and then generate all of the Y1’s and Y2’s based on the values of X that you generate. You can then exploit this stepwise generation procedure to vectorize and parallelize your code. I’ll discuss vectorization to give you a sense of how to exploit the DAG we’ve drawn to write faster code.
Vectorize Your Simulations
Sequential dependencies are a major bottleneck in languages like R and Matlab that cannot perform loops efficiently. Looking at the DAG for the model shown able, you might think that you can’t get around writing a “for” loop to generate samples of this model because some of the variables need to be generated before others.
But, in reality, each individual sample from this model is independent of all of the others. As such, you can draw all of the X’s for all of your different simulations using vectorized code. Below I show how this model could be implemented using loops and then show how this same model could be implemented using vectorized operations:
Loop Code
run.sims <- function(n.sims)
{
results <- data.frame()
for (sim in 1:n.sims)
{
x <- rnorm(1, , 1)
y1 <- runif(1, x, x + 1)
y2 <- runif(1, x - 1, x)
z <- rcauchy(1, y1 + y2, 1)
results <- rbind(
results,
data.frame(X = x, Y1 = y1, Y2 = y2, Z = z)
)
}
return(results)
}
b <- Sys.time()
run.sims(5000)
e <- Sys.time()
e - b
Vectorized Code
run.sims <- function(n.sims)
{
x <- rnorm(n.sims, , 1)
y1 <- runif(n.sims, x, x + 1)
y2 <- runif(n.sims, x - 1, x)
z <- rcauchy(n.sims, y, 1)
results <- data.frame(X = x, Y1 = y1, Y2 = y2, Z = z)
return(results)
}
b <- Sys.time()
run.sims(5000)
e <- Sys.time()
e - b
The performance gains for this example are substantial when you move from the naive loop code to the vectorized code. (NB: There are also some gains from avoiding the repeated calls to rbind, although they are less important than one might think in this case.)
We could go further and parallelize the vectorized code, but this can be tedious to do in R.
The Data Generation / Model Fitting Cycle
Vectorization can make code in languages like R much more efficient. But speed is useless if you’re not generating correct output. For me, the essential test of correctness for a probabilistic model only becomes clear after I’ve written two complementary functions:
- A data generation function that produces samples from my model. We can call this function
generate. The arguments togenerateare the parameters of my model. - A model fitting function that estimates the parameters of my model based on a sample of data. We can call this function
fit. The arguments tofitare the data points we generated usinggenerate
The value of these two functions is that they can be set up to feedback into one another in the cycle shown below:
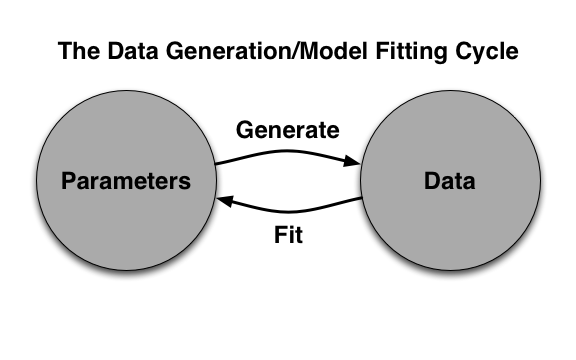
I feel confident in the quality of statistical code when these functions interact stably. If the parameters inferred in a single pass through this loop are close to the original inputs, then my code is likely to work correctly. This amounts to a specific instance of the following design pattern:
data <- generate(model, parameters)
inferred.parameters <- fit(model, data)
reliability <- error(model, parameters, inferred.parameters)
To see this pattern in action, let’s step through a process of generating data from a normal distribution and then fitting a normal to the data we generate. You can think of this as a form of “currying” in which we hardcore the value of the parameter model:
n.sims <- 100
n.obs <- 100
generate.normal <- function(parameters)
{
return(rnorm(n.obs, parameters[1], parameters[2]))
}
fit.normal <- function(data)
{
return(c(mean(data), sd(data)))
}
distance <- function(true.parameters, inferred.parameters)
{
return((true.parameters - inferred.parameters)^2)
}
reliability <- data.frame()
for (sim in 1:n.sims)
{
parameters <- c(runif(1), runif(1))
data <- generate.normal(parameters)
inferred.parameters <- fit.normal(data)
recovery.error <- distance(parameters, inferred.parameters)
reliability <- rbind(
reliability,
data.frame(
True1 = parameters[1],
True2 = parameters[2],
Inferred1 = inferred.parameters[1],
Inferred2 = inferred.parameters[2],
Error1 = recovery.error[1],
Error2 = recovery.error[2])
)
}
If you generate data this way, you will see that our inference code is quite reliable. And you can see that it becomes better if we set n.obs to a larger value like 100,000.
I expect this kind of performance from all of my statistical code. I can’t trust the quality of either generate or fit until I see that they play well together. It is their mutual coherence that inspires faith.
General Lessons
Speed
When writing code in R, you can improve performance by searching for every possible location in which vectorization is possible. Vectorization essentially replaces R’s loops (which are not efficient) with C’s loops (which are efficient) because the computations in a vectorized call are almost always implemented in a language other than R.
Correctness
When writing code for model fitting in any language, you should always insure that your code can infer the parameters of models when given simulated data with known parameter values.